Abstract
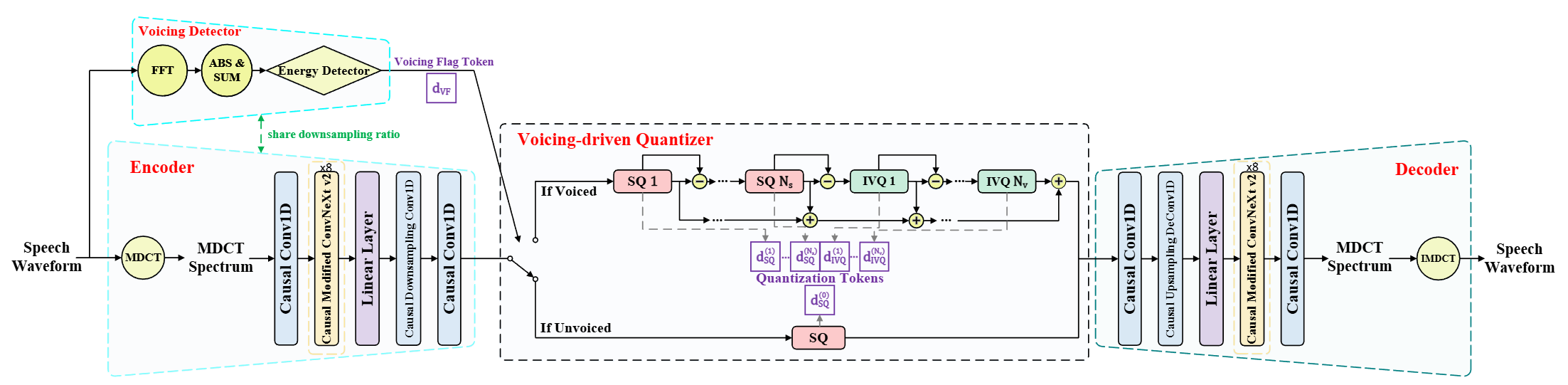
Neural speech codecs, as key components for compressing and reconstructing speech signals, play a significant role in speech transmission and storage. However, most existing codecs employ a uniform quantization strategy across all speech frames, allocating the same bitrate regardless of content. This approach is suboptimal for speech signals, resulting in unnecessary bitrate consumption and leaving potential for further compression. In this paper, we present a low-bitrate streamable neural speech codec called VoCodec. Unlike existing codecs, VoCodec employs a voicing-driven quantization strategy, assigning different bitrates to voiced and unvoiced frames based on their sensitivity to human auditory perception. Specifically, VoCodec incorporates a voicing detector into its fully causal encoder–quantizer–decoder neural coding framework to identify voicing characteristics in the input speech. Based on this, it adopts complex residual scalar-vector quantization for voiced frames and simple scalar quantization for unvoiced frames during quantization. Experiments show that on the LibriTTS dataset at a 16 kHz sampling rate, VoCodec outperforms baseline neural speech codecs even at a bitrate as low as 1.1 kbps. Our further experiments also confirm that introducing voicing-driven quantization can effectively reduce the bitrate by approximately 27% compared to the original uniform quantization strategy.